

Enhancing User Experience with Notion-Style URL Architecture
URL is the web's user interface. While most users today rely on search engines to find websites, URLs remain the core mechanism for accessing any resource on the internet. Understanding URLs—especially their structure and design—is crucial for creating user friendly web applications.
Introduction: Understanding the Power of URLs
What is a URL?
Think of a website like a house: you need an address to reach there. Whether you arrive via GPS (search engines), someone's directions (links), or knowing the address by heart (direct URL), you still need that unique location identifier. The browser's address bar serves exactly this purpose, providing direct access to any resource on the web.
To understand URL structure better, visit howurls.work. In this article, we'll focus specifically on the path component and how thoughtful URL design can enhance user experience.
Why does the path matter?
It doesn’t… to most people using the internet. But to the power users, it’s the way they might access a resource on the server. For example, if you visit arpitdalal.dev/me, you’ll land on my about page. Here, you accessed the me resource on the server where my website is hosted.
That was easy, but let’s take this example to access different repositories and different parts of those repositories on GitHub. On GitHub, every repository has to have an owner account or an owner organization. In the case of github.com/arpitdalal/arpitdalal.dev, arpitdalal is the owner and arpitdalal.dev is the repository. For github.com/remix-run/remix, remix-run is the organization and remix is the repository. You can also directly access the commits on that repository by adding /commits to the URL, github.com/remix-run/remix/commits. Also, individual commits can be accessed like so github.com/remix-run/remix/commit/66bb870c17a4d778a3cff66973fee5314c694f82.
Every page/resource can be accessed via path in a URL.
What does it have to do with Notion?
Notion is built with power users in mind, so they architected their URLs in a really clever way.
In the earlier example of Remix’s individual commit URL on GitHub, could you have guessed what that commit was about? It’s unlikely. The gibberish after /commit/ is an id that GitHub uses to know which commit to show, but it doesn’t help us to understand what the commit is about.
Now if I show you this URL
arpitdalal.notion.site/Arpit-Dalal-115f0f16d2cd80ea8cf0d37ffb8ccfdf
You’ll instantly know that you’re going to a custom Notion site, but read the full path of the URL Arpit-Dalal-115f0f16d2cd80ea8cf0d37ffb8ccfdf. It also has some gibberish but it has Arpit-Dalal in front of that gibberish.
How about this URL?
arpitdalal.notion.site/About-Arpit-Dalal-115f0f16d2cd8029b92ae679687607dd
The path here has About-Arpit-Dalal before the gibberish. Just by reading that you understand that the page has to be about… well… Arpit Dalal.
What if you type this URL in your browser? You get autocomplete on path of the URL that you’re trying to access. By only typing Abo, I already see a suggestion for About-Arpit-Dalal page.
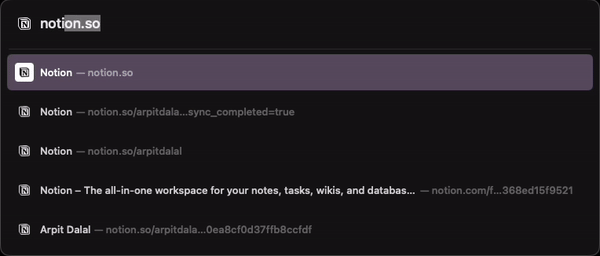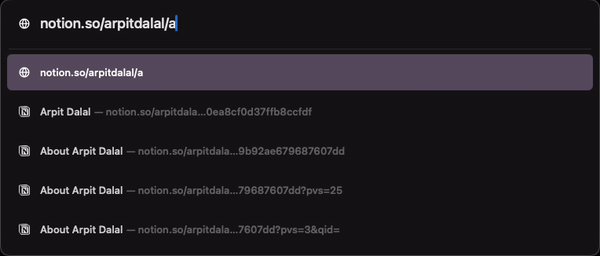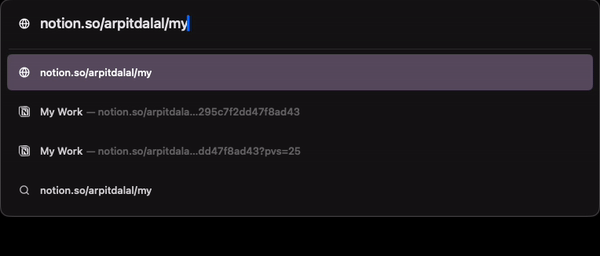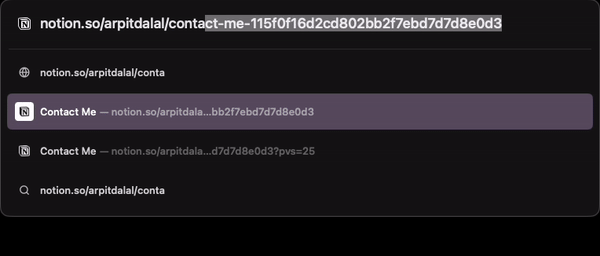
Now imagine trying to access a commit from your project on GitHub, would that be possible? I don’t think so. But, Notion architected their URL paths in a way that the id used internally to identify pages doesn’t really matter when accessing those pages directly through a browser’s address bar.
Implementation: Building Notion-Style URLs
How do these URLs work?
That is a good question. While the exact implementation details aren't public, we can implement it in our own way.
This section will demonstrate a simple app that shows all the posts on the / path and each post details page on /{slug-id} path.
This example uses remix.run to create this app but this URL architecture can be built using any language or framework of your choice.
The Intrinsics
Rather than showing the full application setup, we’ll implement the necessary code to build this architecture.
We’ll first need a function that takes title and id of the post. Then, replace anything other than characters and numbers from the title with a - and then append the id after a - too. There we have the title’s slug prepended to the id.
function getSlugWithId({ title, id }: { title: string; id: string }) {
// Validate inputs
if (!title || !id) {
throw new Error("Title and ID are required");
}
const slugifiedTitle = title
.trim() // Trim the title for any leading/trailing spaces
.replace(/[^a-zA-Z0-9]+/g, "-") // Replace special characters and spaces with hyphens
.replace(/^-+|-+$/g, ""); // Trim any leading/trailing hyphens
// You can lowercase the title too
// I chose not to, to stay in parity with Notion's approach
// Ensure we have valid content before creating slug
if (!slugifiedTitle) {
return id; // Fallback to just ID if title produces empty slug
}
return `${slugifiedTitle}-${id}`;
}
slug-id in the database because if the title of the post changes, then the id also needs to be updated in the database. That might cause issues with caching, database indexes, etc.How to use it?
First, we need to show a link with slug-id for each post to the users. Let’s assume we’re getting the posts from a database as postsData. Then, we’ll need to replace the id with slug-id using our function getSlugWithId.
const posts = postsData.map((post) => ({
...post,
id: getSlugWithId(post),
}));
We can show this data using React but you can choose to show it however you want. post here is a single post object containing title and id.
<Link to={`/${post.id}`}>
<h2>{post.title}</h2>
</Link>
Now that users can go to the post details page /First-Post-aabbccddeeff, we need to retrieve the post details using this id.
Most frameworks will allow you to define dynamic routes, for Remix, the syntax is $postId.tsx. This will ensure that the dynamic value is named postId and can be accessed using params object passed in the loader. You can read more about it on Remix docs.
We have the post id First-Post-aabbccddeeff but we cannot search a post using it as the database doesn’t have slug-id. To remove the slug part from it, we can split the string with - and access the last part of it to retrieve the actual id.
function extractPostId(slugOrId: string): string {
// Validate input
if (!slugOrId) {
throw new Error("Invalid post identifier");
}
// Split the slug-id combination
const parts = slugOrId.split("-");
const id = parts.at(-1);
// Validate that we got a valid ID
if (!id || id.length < 1) {
throw new Error("Invalid post ID format");
}
// Optional: Add validation for expected ID format
// For example, if IDs should be 12 characters
if (!/^[a-f0-9]{12}$/.test(id)) {
throw new Error("Invalid post ID format");
}
return id;
}
// Usage
try {
const postIdRaw = params.postId;
const postId = extractPostId(postIdRaw);
} catch (error) {
// Handle error appropriately
throw new Response("Invalid Post ID", { status: 400 });
}
The split("-").at(-1) method handles both new slug-id URLs and legacy URLs that contain only the id, maintaining backward compatibility. But the split("-") will return our id as the only item in an array if it doesn’t find the separator -, and since there’s only 1 item in the array, at(-1) will give us our id which means we are good on that front too.
Now it’s pretty easy to do a query against your database to find a post with this id and show it to your users.
Using these building blocks, we are able to prepend slug to the id, show it to the users in a link, retrieve it, and separate the slug from the id to retrieve more details. This way, the database stays clean of the slug and only has to care about id and we achieve an amazing UX for the power users who like to access their posts directly from the address bar.
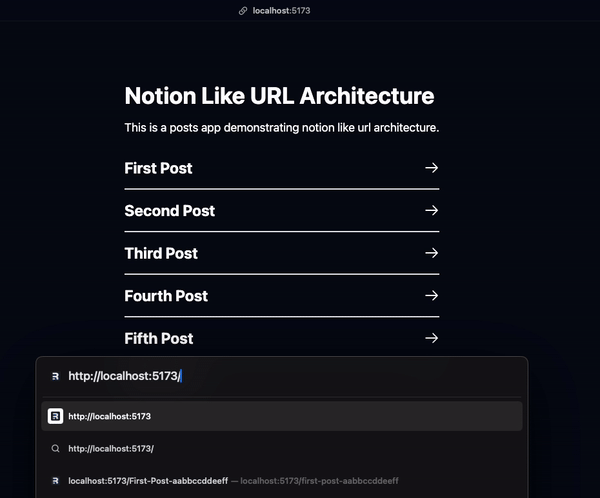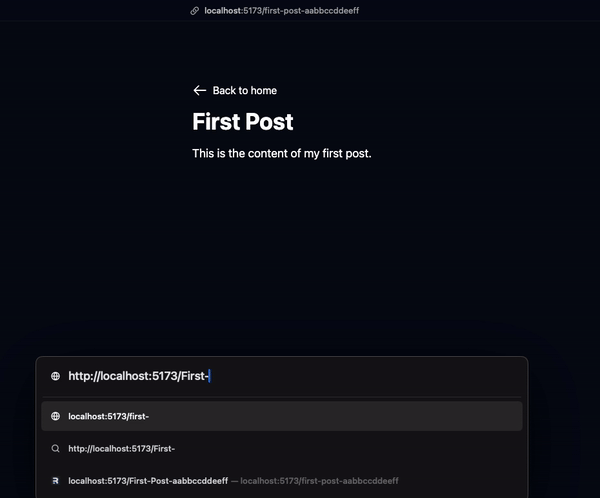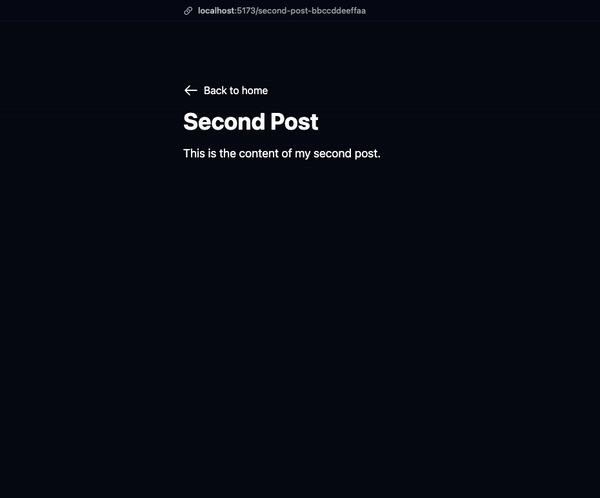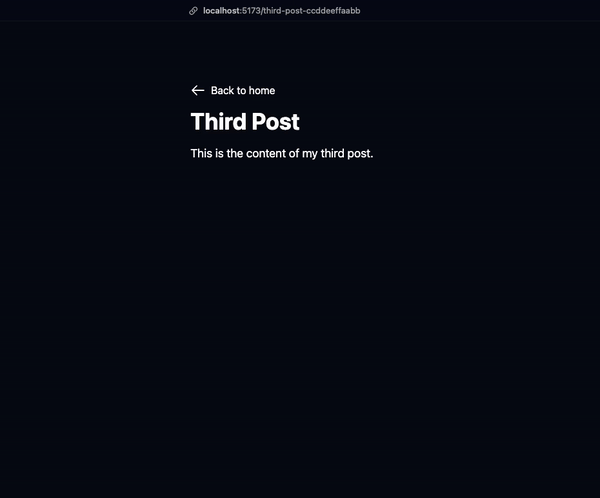
That’s it… is it?
The core functionality is done, but we can improve the UX further by forcing a refresh when a user lands on the post details page without a slug. This will tell their browser that the URL without the slug has been moved to the URL with the slug.
We can easily achieve this by checking if the received postId has a - in it or not. We can rely on this simple check because even if the slug was only 1 word, we’d have a - to separate slug from id like so first-aabbccddeeff.
We already have the id that our database understands so we can directly search it and retrieve its title. Then, we can simply redirect the user to what we receive from our getSlugWithId function.
// Check if we need to redirect
if (!postIdRaw.includes("-")) {
// Attempt to fetch post details
const post = getPostById(postIdRaw);
if (!post) {
throw new Response("Post not found", {
status: 404,
statusText: "Not Found",
});
}
// Generate new slug and redirect
const newSlug = getSlugWithId(post);
// Check if the new slug is different
if (newSlug !== postIdRaw) {
return redirect(`/${newSlug}`);
}
}
Conclusion: Elevating User Experience with Smart URL Design
In conclusion, we explored the impact of URL architecture on user experience. By examining Notion’s approach to URL design, we determined incorporating meaningful slugs alongside ids can improve accessibility and usability for power users. We implemented the Notion-like URL architecture that supports both slug-id and just id in the path part of the URL which increases the user experience. This approach not only maintains a clean database structure but also provides a seamless and intuitive navigation experience for users. The demonstration of this architecture highlights its potential to enhance how users interact with web applications, making it a valuable consideration for developers aiming to provide a remarkable user experience.
You can find the complete code for this demo app on my GitHub or play with the code directly on StackBlitz.
getSlugWithId, extractPostId, and the redirect functionalities.



